Artificiële intelligentie kan tegenwoordig met een tekstuele beschrijving een haarscherpe video genereren. Hoe werkt dat? Wiskundige Ann Dooms legt het uit.
Half februari lanceerde OpenAI zijn nieuwste telg, Sora genaamd. Hiermee kan je met een tekstuele beschrijving een haarscherpe video van een minuut lang genereren. De tool is dus een uitbreiding van hun DALL-E-toepassing, maar om de stap van foto naar video te zetten, was het kloppend hart van ChatGPT nodig. Dit inzicht werd gepubliceerd door William Peebles en Saining Xie in hun artikel Scalable Diffusion Models with Transformers, wat eerder nog de sneer kreeg niet zo vernieuwend te zijn omdat het een cocktail is van twee bestaande ingrediënten. OpenAI zag er wel de kracht van in en stelde Peebles aan om zijn idee in een product te gieten.
Het diffusiemodel werd in 2015 geïntroduceerd als een nieuwe techniek om te leren uit data geïnspireerd op de thermodynamica, een tak uit de natuurkunde. Het model laat toe om de kansverdeling van een gegeven dataset te leren door te kijken hoe de datapunten zich via diffusie tot elkaar verhouden. Eens de verdeling gekend is, kan men dan nieuwe datapunten genereren. Tijdens het leerproces voegt men in verschillende stappen ruis toe aan een heleboel foto’s van eenzelfde object, bijvoorbeeld hamsters. Vervolgens probeert men tijdens het trainen van het model de ruis stapsgewijs weer ongedaan te maken.
Dit lijkt op het eerste gezicht een onmogelijke taak: hoe kan men uit een compleet ruizig beeld de originele foto’s reconstrueren? Dit lukt omdat we per foto het recept leren van hoe hem te bouwen. Een soortgelijk proces zagen we in de column Een encyclopedie op een schijfje over figuren die opgebouwd zijn uit kleinere kopieën van zichzelf, fractalen genaamd. Wanneer men de transformaties die de grote figuur op de kleinere versies afbeeldt, samen herhaaldelijk toepast op een willekeurig startbeeld, dan krijgt men na een tijdje de originele figuur terug. Dit is een toepassing van de meer dan honderd jaar oude Fixpuntstelling uit de analyse, bewezen door Stefan Banach in 1922. De zogenaamde Sierpiński-driehoek is een fractaal die opgebouwd is uit drie kleinere kopieën van zichzelf waarbij de figuur in de lengte en breedte gehalveerd wordt en verschoven naar boven, links en rechts respectievelijk. Wanneer we deze transformaties herhaaldelijk toepassen op een willekeurig startbeeld, verkrijgen we hem terug, uit het niets als het ware.
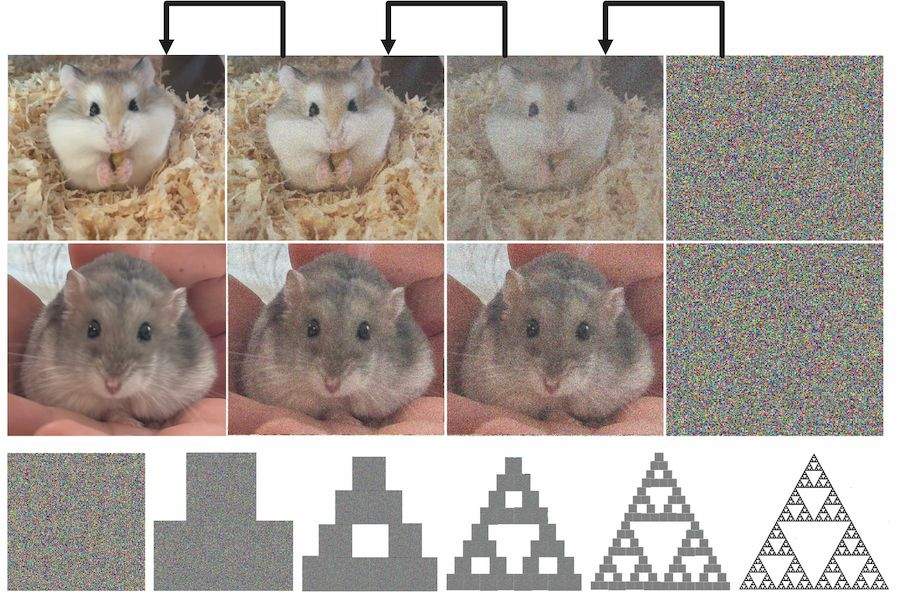
Michael Barnsley bewees vervolgens dat dit proces ook lukt bij niet-fractalen omdat er steeds delen in een figuur kleinere kopieën zijn van andere delen. Je hebt dan natuurlijk veel meer transformaties nodig om te combineren. De neurale netwerken achter het diffusiemodel zijn in staat om tijdens het trainen op een massa data niet alleen zulke transformaties per foto te leren, maar kunnen dit veralgemenen tot het vinden van transformaties waarmee je een hele categorie van objecten kan bouwen, zoals hamsters.
Door tijdens het trainen ook een tekstuele beschrijving mee te nemen van wat er allemaal op een foto staat – verkregen door bijvoorbeeld de captions die onder figuren op het web staan mee te nemen – kan je vervolgens het genereren van beelden van een bepaald object tekstueel sturen. Dit lukt door het diffusiemodel te combineren met de kern van ChatGPT, het transformer model.
Net als bij het leren van taal start men van tokens door de beelden op te delen in blokjes en te kijken welke blokken vaak in mekaars buurt staan. Door dit te combineren met tekstuele beschrijvingen leert het systeem verschillende contexten begrijpen waarin objecten gecombineerd voorkomen. Peebles en zijn team bij OpenAI breidden de techniek vervolgens uit naar video, waardoor het systeem ook weet hoe objecten bewegen. Je begrijpt wel meteen dat dit enkel goed kan lukken wanneer het systeem getraind is op een gigantische hoeveelheid voorbeelden. De huidige versie van Sora (die nog niet publiek toegankelijk is) is dan ook nog niet feilloos en genereert soms zaken die tegen de wetten van de fysica ingaan. Toch zou het toevoegen aan de trainingset van video’s in de trant van de bovenste hamster met beschrijving ‘Hamster die een nootje eet, zittend op een berg zaagsel’ en van de onderste met ‘Hamster zittend op een hand’ ervoor zorgen dat je zonder probleem kan vragen om een video van een hamster die lekker smakkend een nootje eet zittend op de hand van een tapdansende Tom Cruise.
De kracht van deze technologie is dus immens, zeker in de entertainmentsector. Toch is het niet allemaal rozengeur en maneschijn, want het trainen en het genereren komt met een prijskaartje in de vorm van een gigantische energierekening. De volgende stap in onderzoek is dus om dit zuiniger en slimmer aan te pakken, iets wat we alvast in mijn team proberen met wiskunde à la Banach en co.

Doe mee met #eosleeft
Met artificiële intelligentie is het eenvoudiger dan ooit om massaal misinformatie viraal te laten gaan op sociale media. Eos Wetenschap vzw wil een baken zijn voor iedereen die op zoek is naar wetenschappelijk onderbouwde journalistiek.
Dankzij de financiële steun van onze community kunnen we dit onafhankelijk blijven doen zonder beïnvloeding van politieke of commerciële spelers.
Wij verstoppen ons niet achter een paywall, omdat we geloven dat open, kwaliteitsvolle wetenschapsjournalistiek leidt tot een vrijere en betere wereld.
Wil je meer weten over de missie van Eos? Klik hier.
Deel je onze missie? Help mee om onze impact te vergroten.



