
Ziedaar de eerste draftversie van het ‘pangenoom’: een blauwdruk van ons DNA waarin ook de genetische variatie tussen mensen is opgetekend. Op termijn moet dit de referentie worden in genetische onderzoek, en daarmee het huidige ‘lineaire’ referentiegenoom vervangen.
Sinds de publicatie van de volledige lettercode van het menselijk DNA begin deze eeuw, hebben genetici een vertrouwd zicht op de omvang en complexiteit van onze genetische code. Die is ongeveer drie miljard letters (baseparen) lang en omvat een twintigduizendtal eiwitcoderende genen, naast stukken die wellicht invloed op lichamelijke processen hebben via bijvoorbeeld genregulatie.
In de lengte is het menselijk genoom dus goed gekend, maar in de breedte laat die kennis nog te wensen over. Al komt daar nu, ruim twintig jaar na de voltooiing van het historische Human Genome Project, verandering in. Want genetici verbonden in een ander internationaal onderzoeksverband – het Human Pangenome Reference Consortium, gefinancierd door de Institutes of Health in de Verenigde Staten (NIH) – komen deze week naar buiten met hun eerste draft van het zogeheten pangenoom: een blauwdruk van het volledige menselijke DNA waarin ook de genetische variatie tussen mensen is meegenomen. Het is de variatie die er mede voor zorgt dat we allemaal uniek zijn (uitgezonderd misschien identieke tweelingen) en die de basis vormt van de rijke genetische menselijke diversiteit. Ook de zopas gepubliceerde draft van het pangenoom is overigens maar een basis om op verder te werken. Hij is gebaseerd op de geanalyseerde genomen (volledige uitgespelde DNA-sets) van 47 mensen afkomstig uit verschillende delen van de wereld. De komende jaren zal de draft nog verder worden uitgebreid met genomen van een veelvoud aan mensen, niet in de laatste plaats uit Afrika en uit het Midden-Oosten (want die regio’s zijn nu nog wat ondervertegenwoordigd).
‘We zullen nu duizenden complexe genetische varianten kunnen meenemen in studies, terwijl dit voordien veel te ingewikkeld was.’
In het menselijk pangenoom komen dus de genetische codes samen van (voorlopig) 47 mensen. Daardoor zit er evenveel keer meer variatie in dan in het referentiegenoom uit 2001, dat een uitgemiddeld genoom was. Dat laatste genoom heet nu ‘lineair’ te zijn: het geeft het DNA weer van slechts één referentie-individu. Om een idee te geven van de bestaande genetische variatie tussen mensen: in een recente vergelijkende DNA-analyse tussen 64 mensen werden 16 miljoen verschillen in de vorm van enkele-baseparen (zogeheten SNP’s) gevonden, en 2 miljoen in de vorm van langere sequenties.
Het verschil tussen een lineair genoom en een pangenoom, waarbij het laatste het eerste als referentie moet gaan vervangen, toont zich nog het best schematisch. Waar een lineair genoom vaak wordt voorgesteld als een horizontale lijn waarin verschillende sequenties (zoals genen) een andere kleur hebben, kan een pangenoom nog het best worden geïllustreerd op een manier die doet denken aan een overzichtskaart van een metronetwerk. Daarbij staan verschillende lijnen in verschillende kleuren voor de variatie in het menselijke genoom, al vertrekken en eindigen de lijnen wel samen. Net zoals in een metronetwerk kunnen verschillende lijnen dezelfde stations aandoen.
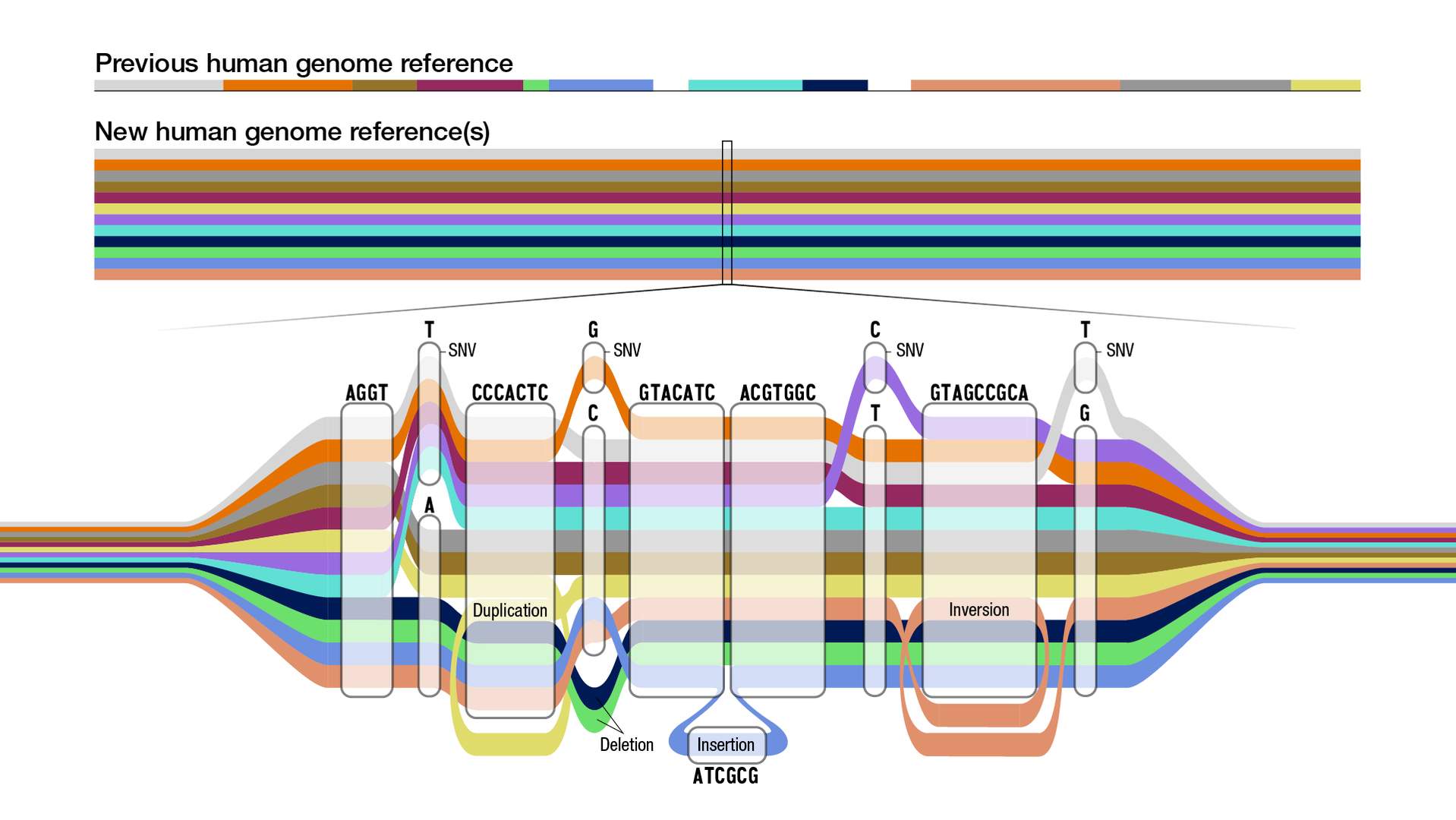
Naarmate het pangenoom het huidige lineaire genoom steeds meer zal verdringen als referentie, zal dit zijn weerslag hebben op het werk van genetici. Geanalyseerd DNA wordt nu nog vergeleken met het laatste, waarna verschillen worden geïnterpreteerd als variaties op deze referentie, of zelfs als afwijkingen. Maar deze verschillen zouden er mogelijk niet geweest zijn, of ze zouden er anders hebben uitgezien, als er al variatie zou hebben gezeten in het referentiegenoom. Door over te schakelen op een pangenoom als referentie zou dit soort bias moeten verdwijnen. Of zoals de Duitse onderzoeker Tobias Marschall, verbonden aan de Heinrich Heine Universiteit in Düsseldorf en een van de vele ‘pangenetici’ meewerken aan dit project, het stelt in een persbericht van de NIH: ‘Door te gaan naar een referentiegenoom dat de wereldwijde genetische diversiteit weergeeft, dringen we bias in interpretaties van DNA-analyses terug. Dat is erg belangrijk, want zulke analyses wordt almaar meer gebruikt in de klinische praktijk.’
Volgens Marschall zal het pangenoom ook toelaten om de genetische component van allerlei ziekten beter te begrijpen. ‘We zullen nu duizenden complexe genetische varianten kunnen meenemen in studies, terwijl dit voordien veel te ingewikkeld was.’
Behalve het reduceren van bias zal het pangenoom er ook voor zorgen dat DNA-sequenties die enkel voorkomen in een subgroep van mensen, niet langer worden genegeerd omdat ze moeilijk passen in één lineair referentiegenoom. ‘Het huidige referentiegenoom heeft grote beperkingen juist doordat het niet de rijke genetische diversiteit weergeeft die voorkomt onder mensen (gemiddeld verschillen we van elkaar in ons DNA met 0,4 procent, red.)’, zegt de Amerikaanse geneticus Ting Wang, geneticus aan de Washington Universiteit in St. Louis. ‘Het is daarenboven ook niet echt, want het is een soort mozaïekgenoom dat bij geen enkele mens voorkomt. Dat is bij het pangenoom dus wel zo. Het bestaat uit volledige DNA-sets van 47 bestaande mensen uit verschillende uithoeken van de wereld. En daar komen er straks nog veel meer bij.



