
Kun je op basis van Google Books-data concluderen dat we steeds emotioneler worden? Taalkundige Hendrik De Smet plaatst vraagtekens bij de onderzoeksvorm die bekend staat als ‘cultural analytics’.
De bevindingen van een recent stuk in PNAS, het gerenomeerde tijdschrift van de Amerikaanse National Academy of Sciences, zullen ongetwijfeld koren op de molen zijn van al wie zich tot enig cultuurpessimisme geroepen voelt. "[O]ur results suggest," aldus de auteurs, "that over the past decades, there has been a marked shift in public interest from the collective to the individual, and from rationality toward emotion." Die conclusie steunt op een complexe statistische analyse van de verschuivingen in de frequenties van 5.000 hoogfrequente woorden in het Engels, gemeten over de voorbije tweehonderd jaar, aan de hand van de data in Google Books. Daarmee lijkt het er dus op dat de auteurs de harde cijfers van big data aan hun kant hebben. De auteurs zelf - Marten Scheffer, Ingrid van de Leemput, Els Weinans, en Johan Bollen - hadden er alvast genoeg vertrouwen in om hun stuk "The rise and fall of rationality" te dopen. Maar voor we besluiten te geloven wat we misschien heimelijk toch al wilden geloven, staan we er best even bij stil dat ook cijfers kunnen misleiden.
Het stuk van Scheffer et al. behoort tot een snelgroeiend type onderzoek, bekend als 'cultural analytics', dat uit verschuivende woordfrequenties in grote historische datasets iets probeert af te leiden over culturele veranderingen. Wie beter wil begrijpen wat dit type onderzoek beoogt kan beginnen bij de Google Ngram Viewer, de toepassing die de centrale dataset van Scheffer et al. ontsluit voor het grote publiek. Open het beginscherm en je wordt meteen aangespoord je zelf aan een rondje cultural analytics te wagen. Op het scherm verschijnt, zoals te zien in Figuur 1 hieronder, een mooie grafiek die doorheen de tijd de veranderende gebruiksfrequentie toont van drie eigennamen - Frankenstein, Sherlock Holmes en Albert Einstein.
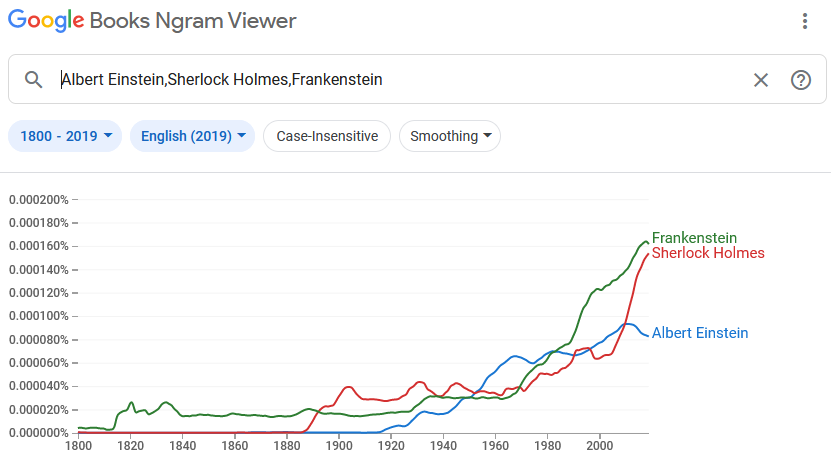
De naam Frankenstein - hoofdpersonage uit de roman van Mary Shelley uit 1818 - verscheen als eerste in het publieke discours, gevolgd door Sherlock Holmes in de tweede helft van de 19e eeuw, en Albert Einstein in de eerste helft van de 20e. Een tijdlang genoot die laatste kennelijk grotere naamsbekendheid dan zijn twee fictieve concurrenten, maar in de late 20e eeuw werd hij opnieuw bijgebeend door Frankenstein, en nog recenter is het vooral Sherlock Holmes die aan een stijle opmars bezig is, en op het punt staat Frankenstein in te halen. Als gebruiker voel je meteen de drang hier een of andere causaliteit achter te zoeken - natuurlijk dat een detective het haalt in deze tijden van complottheorieën, zoiets. Patronen van veranderende woordfrequenties vinden en verklaren, dat is precies wat ook onderzoekers zoals Scheffer et al. proberen te doen, maar dan op grote schaal, en met een uitgebreid arsenaal aan statistische technieken.
Wat aan dit soort ondernemingen zo verlokkelijk is, is dat ze de indruk wekken een onmogelijk complexe culturele werkelijkheid te kunnen vatten in objectieve cijfers. Maar het gevaar van circulariteit schuilt om de hoek, en dan zijn er ook nog tal van technische en taalkundige valkuilen. Niettemin laat de zweem van objectiviteit dit type onderzoek snel ingang vinden in de algemene wetenschappelijke pers en bij het brede publiek. Tijd, ruimte en leesbaarheid laten niet toe dat ik hier alle aspecten van het stuk van Scheffer et al. behandel. Hun argumentatie is complexer dan ik ze hier kan weergeven. Maar gezien hun verregaande claims is het toch wenselijk te wijzen op enkele fundamentele problemen.
Bewijsmateriaal
Het centrale argument van Scheffer et al. luidt dat over de voorbije 200 jaar een grote groep woorden een gelijklopende ontwikkeling kende in hun frequentie. Dat verloop duiden Scheffer et al. aan met "the tilted hockeystick", naar de vorm van de curve. Neem bijvoorbeeld angry. Tot het midden van de 20e eeuw nam de frequentie van angry af, die trend stagneerde even, om dan rond 1980 plots te keren, zoals te zien in Figuur 2 hieronder. (Terzijde: In deze en volgende grafieken heb ik de frequenties gestandaardiseerd, met 1 voor de hoogst gemeten frequentie, en 0 voor de laagste, zodat trends makkelijk in éénzelfde grafiek te tonen zijn. Frequenties zijn ook genormaliseerd, en houden er dus rekening mee dat de geraadpleegde datasets niet voor elk jaar of decennium evenveel data bevatten.)
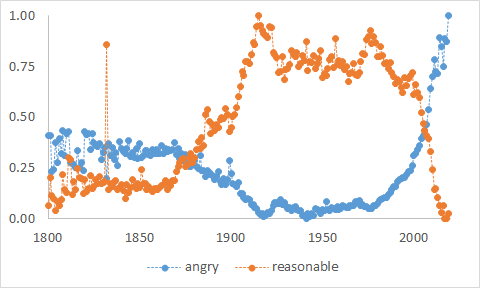
Scheffer et al. argumenteren dat de woorden die dit patroon volgen, zoals angry, overwegend woorden zijn die verwijzen naar gevoelens en individuele ervaring (overwegend is hier trouwens een belangrijke toevoeging, want tot de lijst behoren ook woorden als breakfast, door, hang of sky, die allicht toevallig hetzelfde patroon volgen). Woorden die het omgekeerde patroon volgen zijn er ook. Bijvoorbeeld, reasonable nam eerst toe in frequentie, om dan rond 1980 een plotse duik te nemen, zoals ook te zien in Figuur 2. Dergelijke woorden, aldus Scheffer et al., verwijzen typisch naar wetenschap, redelijkheid, procedures, en zo meer. Samengevat, ergens rond 1980 kantelde onze gezamenlijke interesse. Plots hadden we het liever over gevoelens, volgden we niet meer ons verstand, en primeerde het individuele op het collectieve.
Woordfrequenties
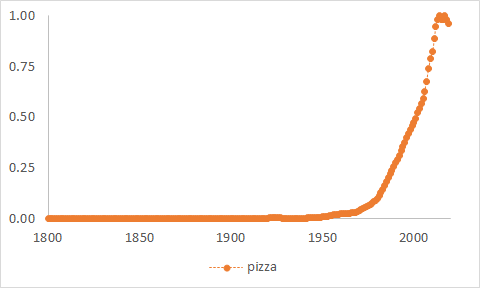
In de grond is het niet onredelijk te verwachten dat een verandering in onze cultuur zich kan manifesteren in ons taalgebruik of, omgekeerd, dat ons taalgebruik iets kan verraden over wat er leeft in onze cultuur. De frequentie waarmee we de woorden voor bepaalde concepten gebruiken kan zich daarbij inderdaad als maatstaf lenen, althans in sommige gevallen. Figuur 3 hieronder toont de frequentie van pizza in het Engels, volgens de gegevens van Google Books. Het is op grond van de grafiek in Figuur 3 aannemelijk dat sprekers van het Engels sinds het midden van de 20e eeuw beduidend meer pizzas zijn gaan eten.
Maar de vertaalslag van woordfrequentie naar historische realiteit is zelden zo eenvoudig. Figuur 4 toont de frequentie van hammer en nails. Als we ons geheel naïef door de cijfers laten meevoeren zouden we kunnen concluderen dat er tussen 1850 en 1930 flink wat is afgehamerd, evenwel zonder corresponderende toenname in het aantal gebruikte spijkers. In de late 20e eeuw nam het spijkergebruik wel plots een hoge vlucht, snel gevolgd door een bescheidener herwaardering van de hamer.
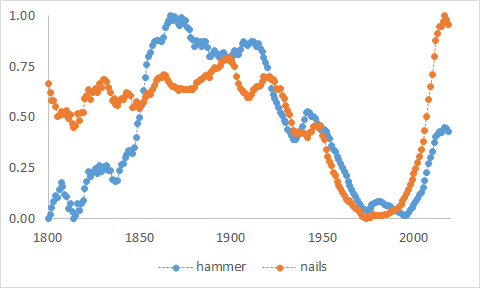
Het voorbeeld legt meteen twee problemen bloot. Ten eerste, woordfrequenties fluctueren om allerlei, soms hoogst onduidelijke redenen. Wie legt me uit waarom de frequentie van hammer verandert zoals ze doet? Van dit eerste probleem zijn Scheffer et al. zich tot op zekere hoogte bewust. Onder andere daarom berust hun analyse niet op de frequentie van één woord, maar op de frequenties van tal van woorden. Toch geloof ik dat ze de moeilijkheden nog onderschatten, zoals zo meteen zal blijken.
Ten tweede, een woord correspondeert niet eenduidig met een concept. Het Engelse nails verwijst eigenlijk niet alleen naar spijkers maar ook naar vingernagels. Als je dus wat wil weten over spijkers heb je niet zoveel aan de frequentie van nails. Taalkundigen noemen zo'n veelheid aan betekenissen polysemie en zijn het erover eens dat polysemie in taal de norm is. Dat wil zeggen, in wezen zijn alle woorden in een taal in meer of mindere mate polyseem (voor wie dat niet gelooft, neem er een woordenboek bij en je zal het zien). Wat een woord in de lijstjes van Scheffer et al. lijkt te betekenen is hooguit onze eerste associatie, bij voorbaat gekleurd door de context van het lijstje zelf. Wat een woord in z'n eigenlijke context betekent is vaak iets helemaal anders. Om maar even een wat willekeurig voorbeeld te geven, Scheffer et al. bestempelen crying als een emotiewoord, maar is het dat ook in de klinische praktijk van een kinderarts, of wanneer het het geluid van zeemeeuwen of de wind aanduidt?
Het ontbreken van een één-op-één-relatie tussen woord en concept trekt zich ook in de andere richting door. Er is typisch meer dan één woord om ongeveer hetzelfde concept uit te drukken. Bijvoorbeeld, de thesaurus van Webster's leert ons dat er in het Engels minstens zo'n 120 verschillende adjectieven bestaan om allerlei schakkeringen van boosheid uit te drukken (disapproving, enraged, icy, indignant, irrascible, passionate, quarrelsome, rancorous, resentful, seething, testy, ticked, worked up, wrathful, enzovoort). De frequentie te kennen van angry volstaat dus niet.
De complexe relatie tussen woorden en concepten komt in het stuk van Scheffer et al. niet eens aan bod. Nochtans is die bijzonder fundamenteel aan hun argumentatie. Doordat er geen één-op-één-relatie is tussen woorden en concepten, kan er ook onmogelijk een één-op-één-relatie bestaan tussen frequentieverandering in het gebruik van woorden en frequentieverandering in het gebruik van de geassocieerde concepten. Geen wonder, dan, dat frequentiecurves al 's vreemde bochten maken, en dat hun interpretatie een hachelijke onderneming is.
Google Books
En dan is er nog een ander, minstens even ernstig probleem. Eigenlijk is Google Books een rommeltje. We weten hooguit bij benadering hoe die enorme dataset intern gestructureerd is. Als je echt wil weten of de frequentie van een woord verandert, dan gebruik je een historisch corpus - een principieel samengestelde verzameling van teksten, die zo goed en zo kwaad als het kan toelaat historische periodes met elkaar te vergelijken. Voor het Engels van de laatste 200 jaar is het Corpus of Historical American English (COHA) de voor de hand liggende keuze. Het is een pak kleiner dan Google Books, maar dat komt vooral omdat Google Books zo onmogelijk groot is. Met 400 miljoen woorden tekst is COHA een van de grootste beschikbare historische corpora, en het is voldoende zorgvuldig samengesteld om te garanderen dat verschillende teksttypes, zoals romans en kranten, evenredig vertegenwoordigd zijn over de decennia. Alleen op die manier kan je veranderingen in woordfrequenties met een enigszins gerust gemoed proberen te meten.
Toetsen we de bevindingen van Scheffer et al. aan COHA, dan blijkt dat de empirische werkelijkheid waarop ze zich beroepen wel eens helemaal niet zo werkelijk zou kunnen zijn. Volgens Scheffer et al. zijn volgende woorden de vijf beste vertegenwoordigers van de "tilted hockeystick": angry, look, walk, unexpected en sleep. Maar hun frequentie in COHA, zoals te zien in Figuur 5, toont iets helemaal anders. Alleen de curve van unexpected benadert de signatuur van de "tilted hockeystick". Angry, look, walk en sleep nemen globaal toe in frequentie en noteren hun hoogste frequentie in de jaren 80 en 90 van de 20e eeuw, net wanneer ze op hun laagst hadden moeten staan.
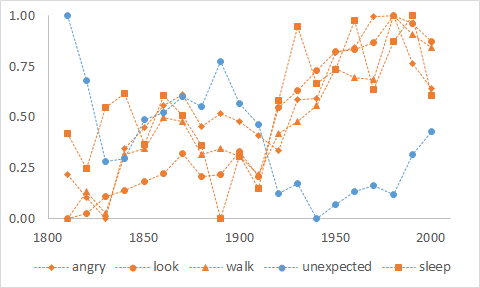
De bevindingen van Scheffer et al. laten zich dus niet goed repliceren in een corpus dat speciaal gemaakt is om historische periodes te vergelijken. Dat COHA een kleinere dataset is, is hier overigens van niet veel tel. De curves zien er dan wel wat hoekiger uit, Figuur 5 hierboven is nog altijd gebaseerd op honderdduizenden observaties. Daar kan een statisticus al wat mee. Maar vanwaar nu die tegenstrijdige resultaten? De meest plausibele uitleg die ik kan bedenken is dat de samenstelling van de data in Google Books verandert met de tijd. Dat ligt vermoedelijk aan de selectieprocedures van Google Books zelf, de selectieprocedures van de bibliotheken waar Google Books de mosterd haalt, de wispelturigheid van de historische overlevering, en reële verandering in de tekstgenres die we lezen en produceren. Toegegeven, die laatste soort veranderingen kan iets zeggen over onze cultuur, want een samenleving die de zondagse preek inruilt voor de sportbijlage van de krant is natuurlijk fundamenteel veranderd. Alleen is het uit de data in Google Books onmogelijk op te maken hoe zwaar die ene factor weegt.
Goed mogelijk dus dat Scheffer et al. met hun "tilted hockeystick" vooral een discontinuïteit ontdekten in de samenstelling van Google Books. Zonder bevestiging op basis van een echt corpus, ben ik daarom weinig geneigd de onderzoeksresultaten van Scheffer et al. zonder meer te accepteren. Scheffer et al. corroboreren hun resultaten wel met gegevens uit andere datasets, maar daarin is van de fameuze "tilted hockeystick" helemaal geen zo'n duidelijk spoor terug te vinden. Vooral de bewering dat de jaren 1980 een scharniermoment vormen in de geschetste ontwikkeling wordt dan erg twijfelachtig - en laat dat nu net het interessantste en vernieuwendste punt zijn in hun betoog.
Feiten en gevoel
Al bij al kan ik hier moeilijk anders concluderen dan dat Big Data, toch in deze, haar beloften niet inlost. Het is prachtig om over veel gegevens te beschikken, maar als je daardoor zelf niet meer goed weet wat je hebt, en bij het bevragen van je data allerlei twijfelachtige aannames moet maken, dan neemt de geloofwaardigheid van de onderzoeksresultaten al snel af. Onderzoek krijgt dan te lijden onder net datgene dat Scheffer et al. als kenmerkend zien voor onze huidige cultuur. Empirische observaties verliezen vaste grond, en het gevoel van de onderzoeker neemt het over: wat plausibel klinkt zal wel waar zijn. Een geluk dat we nog corpora hebben om te blijven hameren op de feiten.



