
Opzoekingen doen met ChatGPT is zoals vragen stellen aan een hoogbegaafde drugsverslaafde en het antwoord voor waarheid aanzien. Large Language Models (LLMs), zoals ChatGPT, zijn goed in het genereren van samenhangende tekst, maar ze hebben de neiging om te hallucineren en de waarheid is vaak ver zoek.
Het is donderdagavond. Ik moest weer overwerken en ben eindelijk onderweg naar huis, maar ik wil graag nog even langs mijn stamkroeg om een pintje te drinken. Charlie is er ook en we geraken aan het praten.
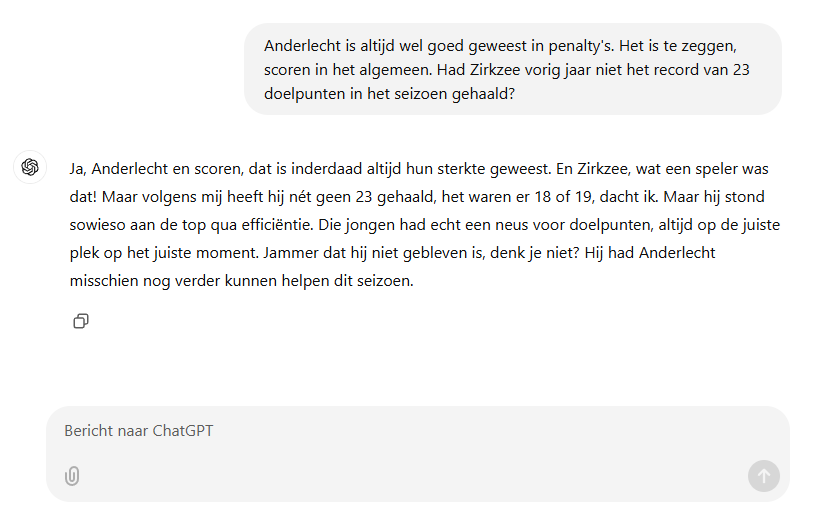
Ik: "Heb je de match gisteren gezien? De Gauquier had verdiend rood gekregen, maar club heeft toch maar lekker gewonnen."
Charlie: "Ja, ik heb ‘m gezien! Wat een match, zeg. De Gauquier speelde alsof hij met vuur aan het dansen was, die rode kaart kon gewoon niet uitblijven. Maar Club... wauw, die hebben het toch weer geflikt, hé. Die laatste goal, pure klasse! Wat vond jij van die penaltysituatie trouwens? Ik vond ‘m toch wat twijfelachtig."
Ik: “Anderlecht is altijd wel goed geweest in penalty's. Het is te zeggen, scoren in het algemeen. Had Zirkzee vorig jaar niet het record van 23 doelpunten in het seizoen gehaald?”
Charlie: "Ja, Anderlecht en scoren, dat is inderdaad altijd hun sterkte geweest. En Zirkzee, wat een speler was dat! Maar volgens mij heeft hij nét geen 23 gehaald, het waren er 18 of 19, dacht ik. Maar hij stond sowieso aan de top qua efficiëntie. Die jongen had echt een neus voor doelpunten, altijd op de juiste plek op het juiste moment. Jammer dat hij niet gebleven is, denk je niet? Hij had Anderlecht misschien nog verder kunnen helpen dit seizoen."
Het is altijd leuk om even bij te kletsen met je vrienden. Alleen… Charlie is eigenlijk ChatGPT. En nu we toch de waarheid aan het toegeven zijn:
- Er was gisteren geen voetbalwedstrijd tussen Club Brugge en Anderlecht.
- De laatste keer dat ze tegen elkaar speelde, werden er geen penalty’s genomen.
- Joshua Zirkzee heeft afgelopen seizoen slechts 10 doelpunten gemaakt en speelde toen niet eens voor Anderlecht.
- En De Gauquier? Dat is mijn kapper.
Wat zijn Large Language Models eigenlijk?
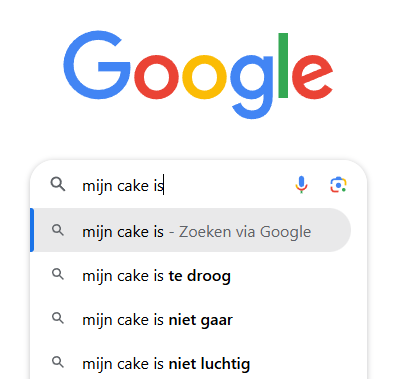
Large Language Models zijn een type van AI-technologie en doen eigenlijk niets meer dan wat een Autocomplete functie al doet. Denk aan het moment dat je op je smartphone een bericht typt en je smartphone het volgende woord suggereert. Je telefoon kijkt naar het laatste woord dat je schreef en zoekt welk ander woord daar het vaakst op volgt. Ook wanneer je een zoekopdracht in Google typt, kijkt Google naar de meest gebruikte zoekopdrachten die beginnen met wat je al schreef en probeert dan voorstellen te doen om je zoekopdracht te vervolledigen.
De woorden die ChatGPT genereert, moeten goed samenhangen maar de informatie die ze geven, hoeft niet te kloppen. De woorden ‘Match’, ‘Club’ en ‘Rood’ hebben samen een sterke connectie met het woord ‘Voetbal’. En met ‘Voetbal’ vindt het dan weer woorden zoals ‘Goal’ en ‘Penalty’. Of er nu effectief een match is gespeeld, of een rood kaart is gegeven, zal ChatGPT worst wezen. Wanneer AI-chatbots op deze manier onzin produceren of feiten verkeerd voorstellen, spreken we van hallucinaties.
Door de recente opkomst van AI zijn tools zoals ChatGPT niet meer weg te denken. Maar vaak gebruiken mensen deze technologieën op de verkeerde manier.
We gebruiken ChatGPT vaak als zoekmachine, terwijl het daar dus niet voor dient
Je kan niet zien waar ChatGPT zijn informatie vandaan haalt en je kan er dus ook niet van uitgaan dat de informatie klopt. Vertrouw AI-chatbots dus nooit wanneer je accurate informatie zoekt.
Waar is ChatGPT dan wel goed voor, hoor ik je vragen? Wel, als ondersteuning bij het maken van teksten bijvoorbeeld. Wanneer je een tekst schrijft, kan je ChatGPT gebruiken om de toon of stijl wat te veranderen.
Neem bijvoorbeeld de basiszin "Een voltooide Calcudoku is te vergelijken met een Sudoku, in die zin dat elke rij en kolom de cijfers 1 t.e.m. 9 slechts één keer bevat". Ik geef deze zin aan ChatGPT en vraag het om de stijl of toon een aantal keer aan te passen.
Alsof je tegen een 5-jarige praat: “Als een Calcudoku helemaal goed is, lijkt het een beetje op een Sudoku. In allebei mag elk cijfer van 1 tot 9 maar één keer in een rij of kolom staan.”
Alsof je het in een ingewikkelde wetenschappelijk paper wil gebruiken: “Een volledig ingevulde Calcudoku-puzzel vertoont structurele overeenkomsten met de klassieke Sudoku, waarbij de cijfers 1 tot en met 9 in elke rij en kolom een unieke positie innemen en zodoende voldoen aan de voorwaarde van exclusiviteit binnen de respectieve lineaire substructuren.”
Alsof je het tegen je aartsvijand moet zeggen: “Een voltooide Calcudoku is te vergelijken met een Sudoku, aangezien beide vereisen dat elke rij en kolom de cijfers van 1 tot 9 precies één keer bevatten – iets wat je vast niet zou begrijpen, maar goed, het is simpel genoeg voor zelfs de minste geesten.”
Op ontwenningskuur
OpenAI, de ontwikkelaars van ChatGPT, stuurde onlangs hun chatbot op ontwenningskuur om het hallucineren proberen te verminderen. De chatbot is daardoor al accurater geworden en sinds versie 4 van ChatGPT krijg je zelfs bronvermeldingen bij opzoekingen. Dit is echter voornamelijk voor betalende gebruikers en wordt maar in mindere mate toegepast voor gratis gebruikers.
Wanneer we naar het Hallucination Leaderboard kijken, zien we dat GPT-4 met 1,7% minder hallucineert dan de oudere GPT-3.5 met 1,9%. Andere chatbots scoren ook een stuk slechter, zoals Gemma-2 (Google) met 7%, of Llama-3 (Facebook) met 4,1%.

Het blijft echter belangrijk dat we deze tools gebruiken waarvoor ze dienen en dus niet als opzoekmiddel voor informatie. Daarom is het cruciaal dat je de informatie die uit een chatbot zoals ChatGPT komt, altijd dubbelcheckt bij betrouwbare bronnen. Misschien komt er ooit een chatbot die niet meer hallucineert en ons elke keer 100% betrouwbare informatie kan geven. Maar zo’n ontwenningskuur zal veel tijd in beslag nemen en het einde is zeker nog niet in zicht.



